跨边缘设备平稳扩展人工智能和计算机视觉

编辑注:insight.tech 支持终止种族主义、不平等和社会不公正的行为。我们不容忍赞助商的产品被用于侵犯人权,包括但不限于政府滥用可视化技术。insight.tech 展示产品、技术和解决方案,并遵循以下前提:负责任和合乎道德地使用人工智能和计算机视觉工具、技术和方法。
自公司推出多核枢轴后的 15 年来,使用多个英特尔® 内核提升性能已经从前沿观念变成普遍行为。人工智能的出现对开发人员提出了一些与十多年前相同的问题。但现在这些问题和新的异构计算环境有关,而这种环境在 2004 年时并不存在。
与典型 CPU(提供一系列完全相同的内核,其中每个内核都适合独立执行)不同的是,CPU + GPU 或 CPU + FPGA 的异构组合会将两个或多个不同组件的计算资源配对。尽管这为在适当环境中实现互利的计算提供了巨大机会,但也增大了正确部署的难度。
部署这些可靠的物联网解决方案的最大用处并不是有利于比复刻更复杂的技术的生存,认清这个事实,您就有了解决问题的方法。
(请注意,就像酸面包一样,这种解决方法并不能适用于所有用处。回答错误。只是一堆问题。)
跨越多项解决方案正确扩展工作负载需要专有技术来构建和部署所需的硬件解决方案,并且首先需要一个允许您开发和测试这些解决方案的软件环境。英特尔® OpenVINO™ 工具套件专为帮助公司在针对同构和异构计算环境开发解决方案时跨多类设备扩展而设计。
OpenVINO 中引入的人工智能和机器学习算法引起了很多关注,但“V”代表“视觉 (Visual)”,并且该工具套件的许多功能预训练模型都专门与计算机视觉相关。
跨硬件平台扩展
OpenVINO 的设计旨在通过支持 OpenVX 和 OpenCL 等跨平台 API 使工作负载可以跨 CPU 和附属加速器执行。(图 1)。
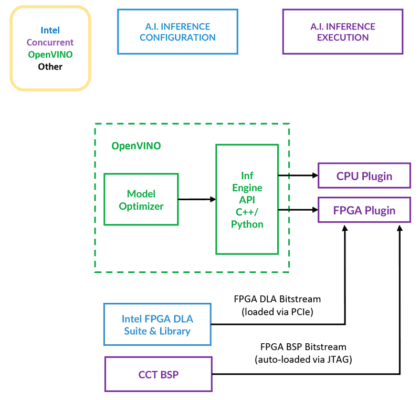
但是如果没有兼容的硬件,软件就没有多大用处,这时就需要来自 Concurrent Technologies 的 TR H4x/3sd-RCx 等解决方案发挥作用。其基础系统是一个拥有 12 核/24 线程英特尔® 至强® D-1559 和高达 64 GB RAM 的 3U VPX 系统。
如果这些功能不足以满足客户需求,还可以选择通过 PCIe 连接更多处理资源。TR H4x/3sd-RCx 还可以通过 PCIe 与英特尔® Arria® FPGA 配对,以提高处理能力。
优化计算机视觉模型
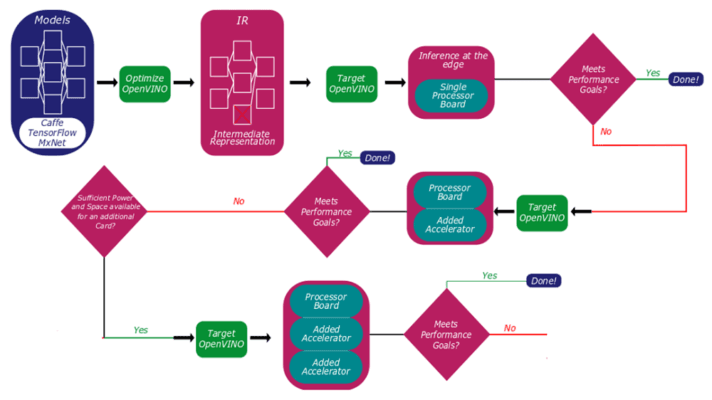
使用 OpenVINO,客户可以构建和优化模型,并测试其解决方案的性能,从单处理器主板开始,并根据需要扩展至更多处理资源(图 2)。
“将您的模型转移到 CPU 上工作很简单;我们提供广泛的 Linux 支持包,” Concurrent Technologies 业务开发总监 Nigel Forrester 说。“将模型转移到 TR H4x 卡上有一点复杂。我们提供一个主板支持版,将它预先加载在卡上,并且提供了在英特尔 Aria FPGA 卡上运行的 DLA(深度学习加速器)比特流。”
“客户唯一要了解的,” Forrester 继续说道,“就是需要什么样的神经网络模型。他们选择正确的 DLA 比特流,采用其现有模型,并通过 OpenVINO 运行这个模型。这提供了一个中间表示,这个中间表示加载到加速器上,使服务器能够全部正常工作。”
之后,OpenVINO 会借助在 CPU 上优化和执行的 CPU 特定代码处理项目分配,而 FPGA 代码则被保留并在 Arria 硬件上运行。
“我们有英特尔® 深度学习加速器套件(英特尔® DLA)开发者许可,并已将其移植到我们的 Trax 卡中,” Forrester 告诉我们。“客户无需做任何事。他们只需要了解他们的神经网络模型是否属于 AlexNet、SqueezeNet、GoogleNet 或其他模型,并且是否处于 TensorFlow 等框架内。”
上图显示了在 Concurrent TR H4x/3sd-RCx 硬件上对 OpenVINO 模型进行资格认证的过程。这个过程会进行一系列优化、性能测试和硬件部署,旨在帮助开发者确定需要将哪类资源专用于哪种工作负载。随着新的英特尔 GPU 和推理加速器进入市场,OpenVINO 未来几年将变得更有用,这将扩展软件的整体灵活性,并允许开发人员针对更广泛的用例和场景进行开发。