物联网数据分析:层析法

边缘(互联网与现实世界交接处)的许多传感设备可以生成大量原始数据。难点在于将原始数据转换为具有可操作性的信息。
原始物联网数据来自许多来源,并以多种形式到达。某些数据可能是连续的,实时捕获的,并使用各种通信机制和协议进行传递。在其他情况下,批处理数据可能源自数据库或内容管理系统,或者以逗号分隔值 (CSV) 文件的形式到达。
物联网应用的基础是使这些数据可用和具可操作性。但是,捕获如此多种不同形状和大小的数据可能会面临挑战,特别是对于基于集中式关系数据库(如 SQL)的系统而言,这种数据库最适合高度结构化的数据。
如今,许多物联网解决方案都依靠云来进行数据存储和分析,但是云并不是解决每个问题的灵丹妙药:
- 带宽不是免费的。将每个数据样本发送到云端都需要花钱。
- 延迟是一个令人关切的问题。某些系统需要实时监视和控制。
- 但无法保证始终连通。对于某些应用而言,要求必须能够独立于云连接运行。
就像传入数据源可能是多种多样且高度分散的方式一样,处理该数据的数据库和分析解决方案也必须如此。
在分布式处理模型中,某些处理在边缘执行,某些处理在雾中(局部的小型云)执行,而某些处理在云端执行。(图 1)。这意味着,如果传感器由于任何原因与主机断开连接,它可以在等待恢复连接的同时继续收集数据。同样,如果设施失去了与云端的连接,仍可继续在雾中以本地方式运行,并在恢复与外界的连接后与云端重新同步。
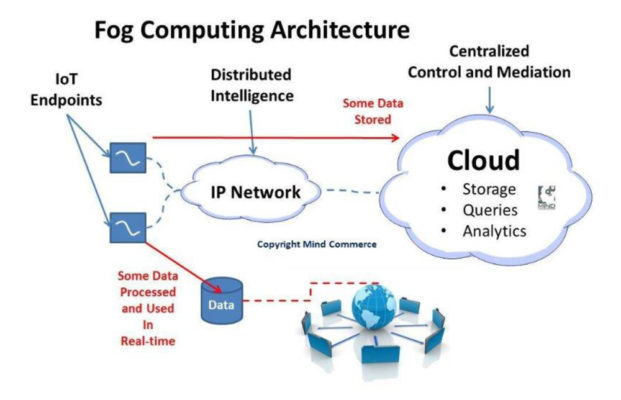
无处不在的分析
正如分布式处理可以降低风险并使万物保持移动一样,分布式分析解决方案也可以在边缘、雾中和云端发挥其魔力。
可以考虑 SkyFoundry 的 SkySpark。这个开放的分布式数据分析解决方案可以跨越边缘到云的连续性从物联网端点收集、存储、分析和呈现数据(图 2)。
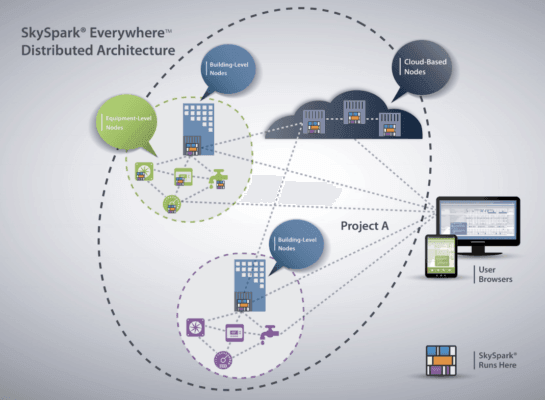
当涉及到各种类型的数据时,SkySpark 平台支持广泛的行业协议,包括 Modbus TCP、BACnet IP、MQTT、Obix 和 OPC UA。这些数据包被封装在称为 Arcbeam 的基于 Web 套接字的对等通信协议中。该协议支持分布式节点与 SQL 和 CSV/Excel 等数据库之间的通信。
SkySpark 还采用了 Folio Time Series Database,有时也称为过程历史记录。该数据库旨在接受模拟或数字样本、设定值和命令形式的大量高速传感器数据。与现成的关系数据库(例如 MySQL 和 MS-SQL)相比,Folio Time Series Database 的架构可以对带时间戳的传感器数据进行最佳处理,而无需任何取舍。
然后,可以提取从 Folio Time Series Database 中提取的数据,并将其显示在用户可配置的 SkySpark 可视化仪表板中(图 3)。

在后端,SkySpark 信息平台提供了包含 500 多种股票分析功能的库,这些功能可应用于在分布式节点上捕获的数据。它还集成了一个称为 Axon 的分析引擎,该引擎使领域专家可以实施最适合其独特应用程序、系统和设备需求的规则和算法。
这些分析算法可以帮助工程师确定模式、偏差、故障以及从边缘到雾再到云端的所有节点的运营改进机会。
即使具有其所有功能和特性,SkySpark 也需要至少 512 MB 的系统 RAM 和 1 GHz 的时钟速度 — 换句话说,该设备能够支持 Java 虚拟机 (VM)。这使得该技术非常适合端到端物联网部署的可扩展计算需求,而这些部署依赖于边缘的英特尔凌动® 处理器,雾中的英特尔® 赛扬® 或英特尔® 酷睿™ 处理器或云端的英特尔® 至强® 处理器。
多层次的情报提供深入的见解
通过比较来自同一业务、使用类似机器和/或采用类似做法的多个位置(写字楼、工厂、农场等)的数据来产生真正的物联网价值。例如,当确定异常温度曲线与异常振动模式共同导致某位置上特定类型的机器出现特定故障时,如果在完全不同的位置观测到同类机器有类似活动,便会触发预防性维护。这可以最大限度地减少停机时间,并降低成本。
长时间收集、分析和关联数据,甚至能获得更多的价值。这不仅仅意味着“从现在开始”。在许多情况下,可能需要访问过去几年甚至几十年的历史数据。通过复杂的分析算法可以挖掘此类历史数据,从而发现“宝藏”并提供丰富的见解。
从边缘到云端的分布式、多层数据分析可以识别看似不相关的输入之间的复杂关系,检测指示未来问题的趋势,进行预测并提供解决方案。