监控服务器的 AI 性能翻番
AI 和机器学习能够为大规模监控系统(例如智能城市部署的监控系统)增加巨大的价值。 机器智能可以帮助缓解交通堵塞,监控敏感地点以及履行许多其他职责。
例如,有一个新出现的基于 AI 的视频监控领域 — 行为分析,监控系统通过行为分析来“学习”被监控环境(例如人行道)的典型行为并报告反常事件(例如一辆车停在路缘上)。 将此应用更进一步便是事件驱动的监控,很多行为(例如有人在指定时间以外进入禁区)均可触发响应(例如言语警告入侵者正在侵入禁区)。
这些功能要求强大的计算性能,一般情况下,只有大型数据中心环境才具备。 这种情况对系统运营商所造成的挑战就是流式传输视频会消耗大量网络带宽,导致传输成本高昂。 某些应用还会在将视频传输到第三方数据中心的过程中遇到额外的延迟。
对于寻求部署人工智能监控系统的运营商而言,一个解决方案便是采用新款英特尔® 至强® 可扩展家族产品(原代号为“Purley”),AI 工作负载性能提升一倍以上。 如图 1 所示,平台的关键特性包括:
- 每插槽高达 28 个内核,上一代产品最多 24 个内核
- 英特尔® 高级矢量扩展 512(英特尔® AVX-512),使得矩阵数学吞吐量翻番
- 新款网格互联架构降低了延迟,提高了内存带宽
- 下一代英特尔® Omni-Path 架构(英特尔® OPA)交换结技术,支持扩展到数万个节点
简而言之,借助至强® 可扩展处理器可以打造高级边缘服务器,满足不断发展的智能城市要求。
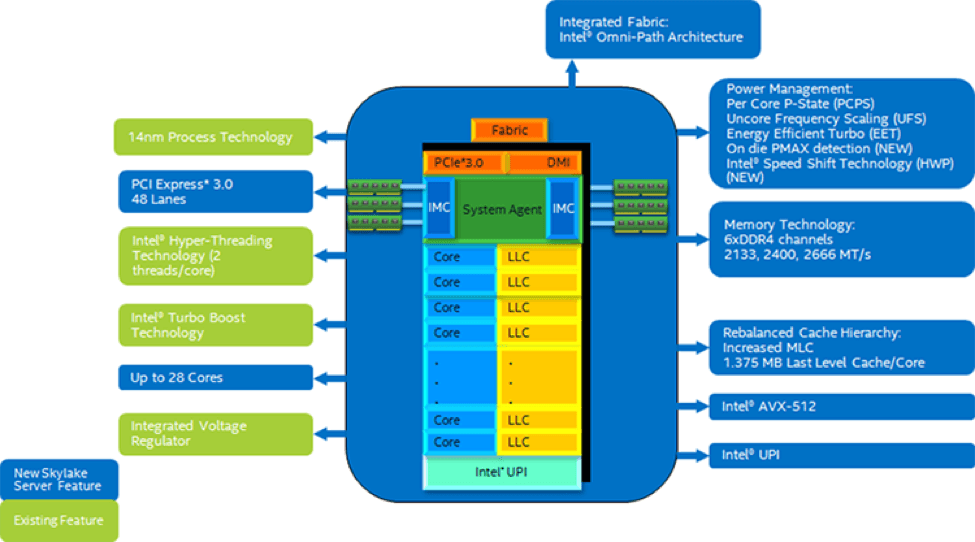
图 1. 英特尔® 至强® 可扩展处理器提供了多项重大增强功能,改进了 DSS 系统的视频分析和 AI 工作负载性能。 (资料来源:英特尔)
让更接近边缘的 AI 计算吞吐量翻番
每插槽高达 28 个内核,8 插槽系统多达 224 个内核,每个内核的时钟速度为 1.9 GHz 至 3.6 GHz,实现性能升级。 此外,每个内核均支持英特尔® AVX-512 SIMD 指令。
英特尔® AVX-512 指令对于英特尔® 处理器并非新鲜事物(英特尔® 至强融核™ 产品线早已采用),因为有多个 512 位新指令定向处理高性能计算 (HPC) 工作负载,其计算吞吐量相当于英特尔® AVX/AVX2 的两倍。 尤其是在监控领域,AVX512DQ 指令增强了光线跟踪的整数和浮点运算、双精度矩阵乘法、快速傅里叶变换 (FFT) 以及视频分析和 AI 应用卷积工作负载指示。
为了支持这些更为复杂的指令,两个融合乘加 (FMA) 单元已从 256 位升级到 512 位。 通过以 a + b * c 的形式计算整体表达式,然后向下取整到最近的有效位,FMA 单元提高了复杂浮点运算的精度。 这使得信号处理应用(例如视频分析)以及其他程序 — 涉及卷积和深度神经网络(CNN 和 DNN)等多项输入累积 — 的分辨率更高。
而且,新款英特尔® 至强® 可扩展处理器相比上一代产品,在深度学习训练和推断性能方面的提升达 2.2 倍,这对基于 AI 的视频分析至关重要。
网格互联降低了延迟,充分发挥出 DSS 的性能
为了充分发挥内核数量增加和英特尔® 至强可扩展处理器集成加速功能所提供的性能,14 纳米 Skylake-SP 微体系结构采用了全新的片上网格互联拓扑技术,降低了内核与内核通信的延迟。
如图 2A 和 2B 所示,网格互联取代了上一代微体系结构的环形拓扑,可以在尽可能最短的垂直/水平路径上实现通信。 高速缓存代理、主代理和 I/O 子系统也集成到网格中,以便在访问这些功能时,内核也可以受益于延迟降低。
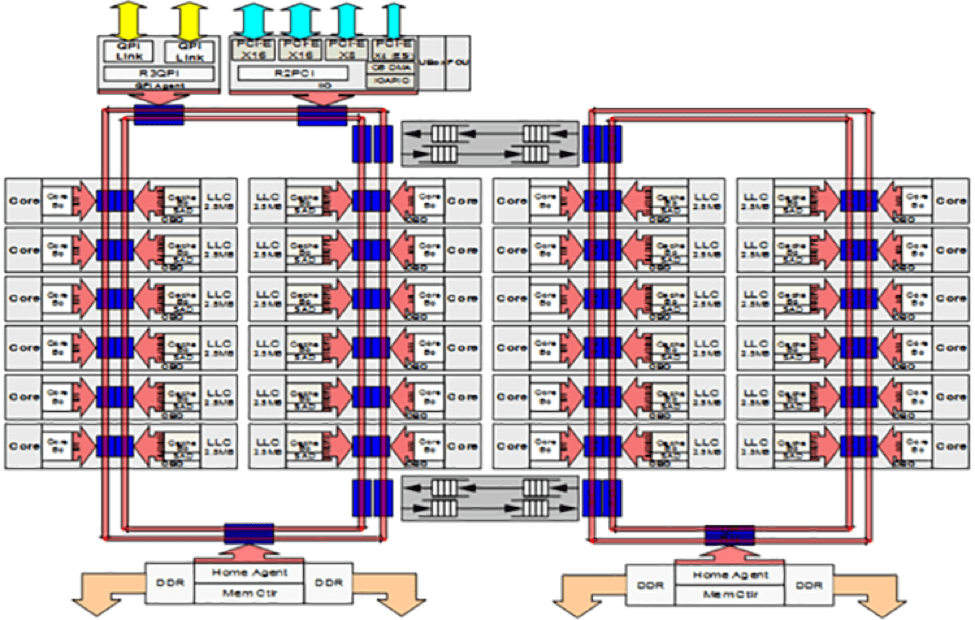
图 2A. 上一代微体系结构的环形互联拓扑会在高吞吐量系统中造成性能瓶颈。 (资料来源:英特尔)
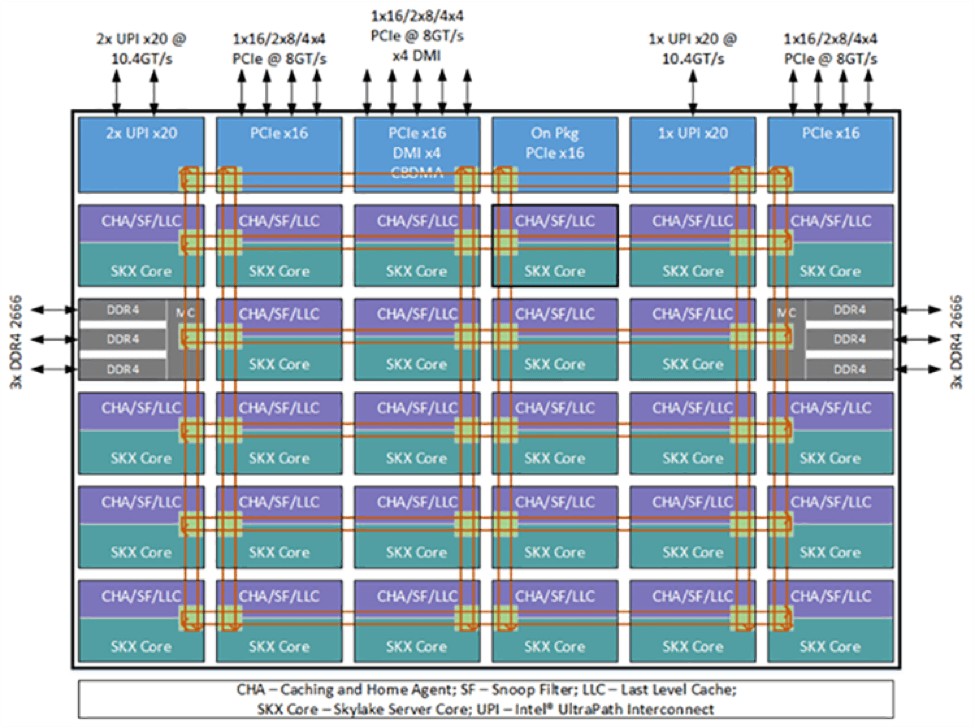
图 2B. 英特尔® 至强® 可扩展处理器的网格互联拓扑通过提供尽可能最短的通信路径来降低内核与内核的通信延迟。 (资料来源:英特尔)
重新设计的高速缓存层次结构使 L1 高速缓存容量翻倍,L2 高速缓存增加到 1 MB,每个内核的最新级别高速缓存 (LLC) 降低至非独占的 1.375 MB(图 3)。 靠近内核重新分配更多高速缓存可以缩短至强® 可扩展处理器的内存访问延迟,转型为非独占 LLC 也获得了更好的总体内存利用率。
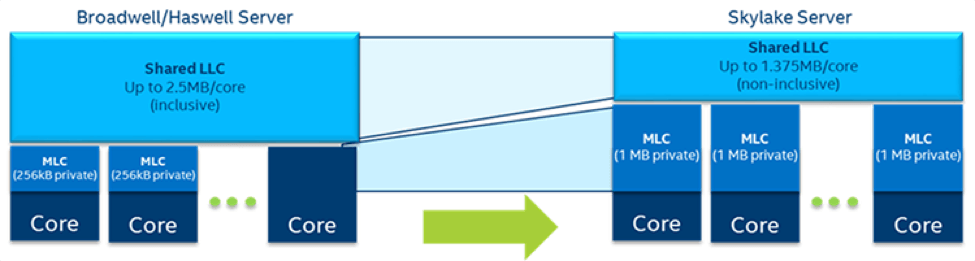
图 3. 相比以前各代的处理器,靠近内核增加高速缓存降低了英特尔® 至强® 可扩展处理器的内存访问延迟。 (资料来源:英特尔)
对于高速缓存需求量大的监控应用来说,这些特性使内存带宽提升了 1.5 倍。 6 通道 2133 至 2666 MHz DDR4 SDRAM 内存性能进一步提升,每个 CPU 的内存容量可高达 1.5 TB。
扩展到百万兆级
监控服务器通常都是多芯片、多插槽系统,因此要求插槽与服务器机架之间以及内核与内核之间实现高速、低延迟通信。
对于芯片与芯片之间的通信,英特尔® 至强® 可扩展处理器提供了可观的高速 I/O 增强,包括每个 CPU 48 条 PCIe 3.0 通道,高达 14 个 SATA3 端口,10 个 USB 3.0 端口以及集成的英特尔® 以太网连接 X722。
但为了使多插槽通信与英特尔® 至强® 可扩展处理器保持同等水平,英特尔® 快速通道互联(英特尔® QPI)已被每个处理器搭配两个或三个英特尔超级通道互联(英特尔® UPI)所取代。 英特尔® UPI 是一项相干互联技术,提供 10.4 GTps 插槽间数据传输速度,集成了一个合并的高速缓存和主代理 (CHA),分布在每个内核及 LLC 库中,从而简化扩展(图 4)。
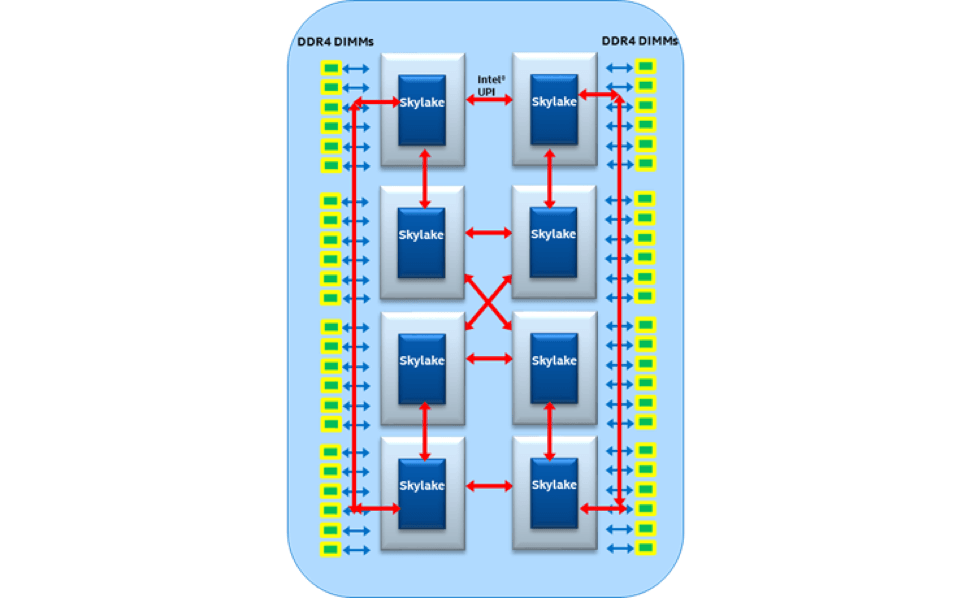
图 4. 英特尔® UPI 是一项高速缓存相干插槽间互联技术,支持 10.4 GTps 数据传输速度。
英特尔® 至强® 可扩展处理器超越单独的系统,支持英特尔® Omni-Path 架构(英特尔® OPA),这是价格极具竞争力的一款英特尔® True Scale Fabric 和 InfiniBand 后续产品,提供 100 Gbps 线路速率,并且可以扩展支持 10,000 个以上的节点。
英特尔® OPA 降低了支持百万兆级计算的硬件要求,同时与旧式交换技术保持软件兼容,在这两方面表现相当出色。 将自适应/分散路由、流量优化、动态通道扩展以及数据包完整性保护等功能集成在一项技术中,便不再需要边缘交换机,最大限度地缩小了机架空间,线缆用量降低一半,从而节约大量成本,显著减少维护工作(图 5)。
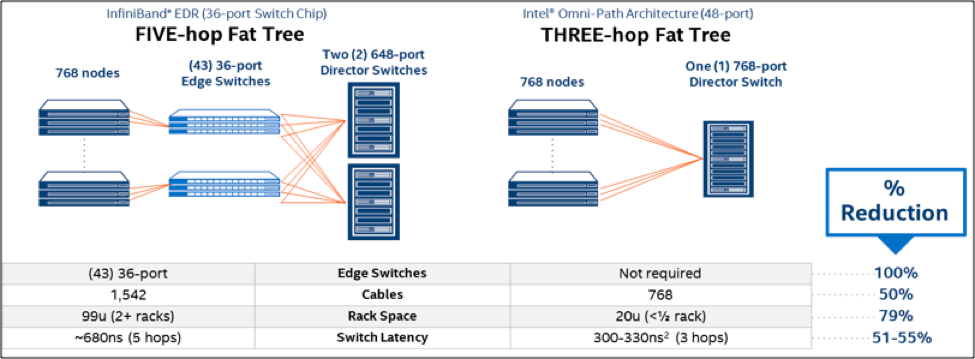
图 5 | 除了提供能够支持 10,000 个以上节点的基础设施之外,英特尔® OPA 还降低了百万兆级计算部署对于硬件的要求。
英特尔® OPA 技术可作为某些英特尔® 至强可扩展处理器 SKU 的集成功能,也可以通过融入到监控服务器设计的插卡来访问。
监控服务器构建模块
基于英特尔® 至强® 可扩展处理器的 DSS 服务器解决方案可以从嵌入式和网络市场的原始设备制造商那里订购。
例如,EnnoconnNSB-1021 便是一款集成网络主板,支持多达两个 24 内核英特尔® 至强® 可扩展处理器、两个英特尔® C620 系列配套芯片组、每个 CPU 多达 48 条 PCI Express 3.0 通道以及六通道高速 DDR4 SDRAM(热设计功耗 (TDP) 范围低至 70 W)(图 6)。

图 6. Ennoconn NSB-1021 是一款适合边缘服务器开发的优秀入门级产品。 (来源:Ennoconn)
得益于新款英特尔® 至强® 可扩展处理器的多功能性以及英特尔® UPI 和英特尔® OPA 等特性,监控系统开发人员可以选用各款高性价比和单位功率性能高的 NSB-1021,然后在需求增长时扩展为本地化服务器阵列库。
使用英特尔® 至强® 可扩展处理器的监控更智能
监控系统集成了 AI 等高级技术以满足智能城市的需求,因此降低网络传输成本和实现更低延迟便是必须解决的两个方面。 实现这两个目标的方法之一便是将能够执行视频分析的监控服务器靠近视频来源放置。
由于只有数据中心才能执行高级视频分析和 AI 工作负载,因此新款英特尔® 至强® 可扩展处理器为监控和智能城市运营商提供了一个替代方案,就是使智能技术更靠近边缘。 监控变得更加智能。